Managing Database Transactions: The Unit of Work Pattern
In our previous article, we discovered how managing transactions at the repository level can lead to dangerous data inconsistencies. A simple user registration system revealed how independently managed transactions could leave our database in an invalid state - an account without its required admin user. Today, we’ll explore a pattern that elegantly solves these challenges while maintaining clean architecture principles.
The Gap Between Business and Technical Reality
Consider what happens when a product manager asks: “Can we add user registration to our platform?” From their perspective, this is a single, indivisible operation. Yet our initial implementation split it into separate database transactions, creating a dangerous gap between business expectations and technical reality.
This disconnect reveals a fundamental challenge in transaction management: how do we maintain clean separation of concerns while ensuring our data changes match business operations? The Unit of Work pattern provides an elegant solution to this challenge.
Understanding the Unit of Work Pattern
The Unit of Work pattern, first described by Martin Fowler, maintains a list of objects affected by a business transaction and coordinates the writing out of changes. Think of it like a shopping cart for your database operations - just as you wouldn’t want half your groceries to check out while the rest fail, we don’t want half our database operations to commit while others roll back.
In its classic form, the pattern tracks:
- Objects that have been modified
- Objects that need to be inserted
- Objects that need to be deleted
However, modern ORMs like SQLAlchemy handle much of this object tracking for us. When using SQLAlchemy, the Session acts as our Unit of Work, tracking changes to objects and coordinating how these changes are persisted to the database.
Let’s look at how this plays out in our implementation:
- The Session tracks all loaded and attached objects
- Any modifications to these objects are automatically detected
- When we commit the transaction, all changes are written as a single unit
This approach keeps our repositories focused on persistence logic while the Session handles the complexities of change tracking and transaction management. Here’s how we structure our code to leverage this:
class CreateAccountUseCase(UseCase[CreateAccountCommand, tuple[Account, User]]):
_session_factory: sessionmaker[Session]
_password_hashing_service: AbstractPasswordHasher
def _execute(self, command: CreateAccountCommand) -> tuple[Account, User]:
password_hash = self._password_hashing_service.hash(command.password)
user, account = User.create_with_account(command.email, password_hash)
with self._session_factory() as session:
# Repositories now focus purely on persistence logic
user_repository = UserRepository(session)
account_repository = AccountRepository(session)
# A single transaction ensures all changes succeed or fail together
with session.begin():
account_repository.save(account)
user_repository.save(user)
return account, user
Note how the transaction now wraps both operations. Our repositories become simpler, focusing purely on persistence:
class AccountRepository:
def save(self, entity: Account) -> None:
model = self.to_model(entity)
self._session.add(model) # No more transaction management
class UserRepository:
def save(self, entity: User) -> None:
model = self.to_model(entity)
self._session.add(model) # Pure persistence concerns
This restructuring brings several immediate benefits:
- Business Alignment: Transaction boundaries now match business operations
- Clear Responsibilities: Repositories focus solely on persistence
- Simplified Testing: Transactions have clear start and end points
- Improved Reliability: Related changes succeed or fail together
Our tests now confirm we’ve solved the partial commit problem:
def test_demonstrates_atomic_operations(use_case: CreateAccountUseCase, session_factory: sessionmaker[Session]) -> None:
# Arrange
command = CreateAccountCommand(
email="john@example.com",
password="password",
password_confirmation="password"
)
# Act & Assert
use_case(command) # First creation succeeds
with pytest.raises(IntegrityError): # Second creation fails atomically
use_case(command)
# Verify no data inconsistencies
with session_factory() as session:
orphaned_accounts = (
session.execute(
select(AccountModel)
.outerjoin(UserModel)
.where(UserModel.uid.is_(None))
).scalars().all()
)
assert len(orphaned_accounts) == 0 # No more orphaned accounts
When Simple Transactions Aren’t Enough
While this pattern solves our immediate problem, real applications quickly reveal more complex challenges. Let’s explore these through a common requirement: sending welcome emails to new users.
class CreateAccountWithWelcomeUseCase(UseCase[CreateAccountCommand, tuple[Account, User]]):
def _execute(self, command: CreateAccountCommand) -> tuple[Account, User]:
account, user = self._create_account(command) # First transaction
self._send_welcome( # Second transaction
SendWelcomeEmailCommand(user_id=user.id, email=user.email)
)
return account, user
class SendWelcomeEmailUseCase(UseCase[SendWelcomeEmailCommand, None]):
def _execute(self, command: SendWelcomeEmailCommand) -> None:
with self._session_factory() as session:
notification_repository = NotificationRepository(session)
with session.begin():
notification = WelcomeEmailNotification(user_id=command.user_id)
notification_repository.save(notification)
self._email_service.send(command.email)
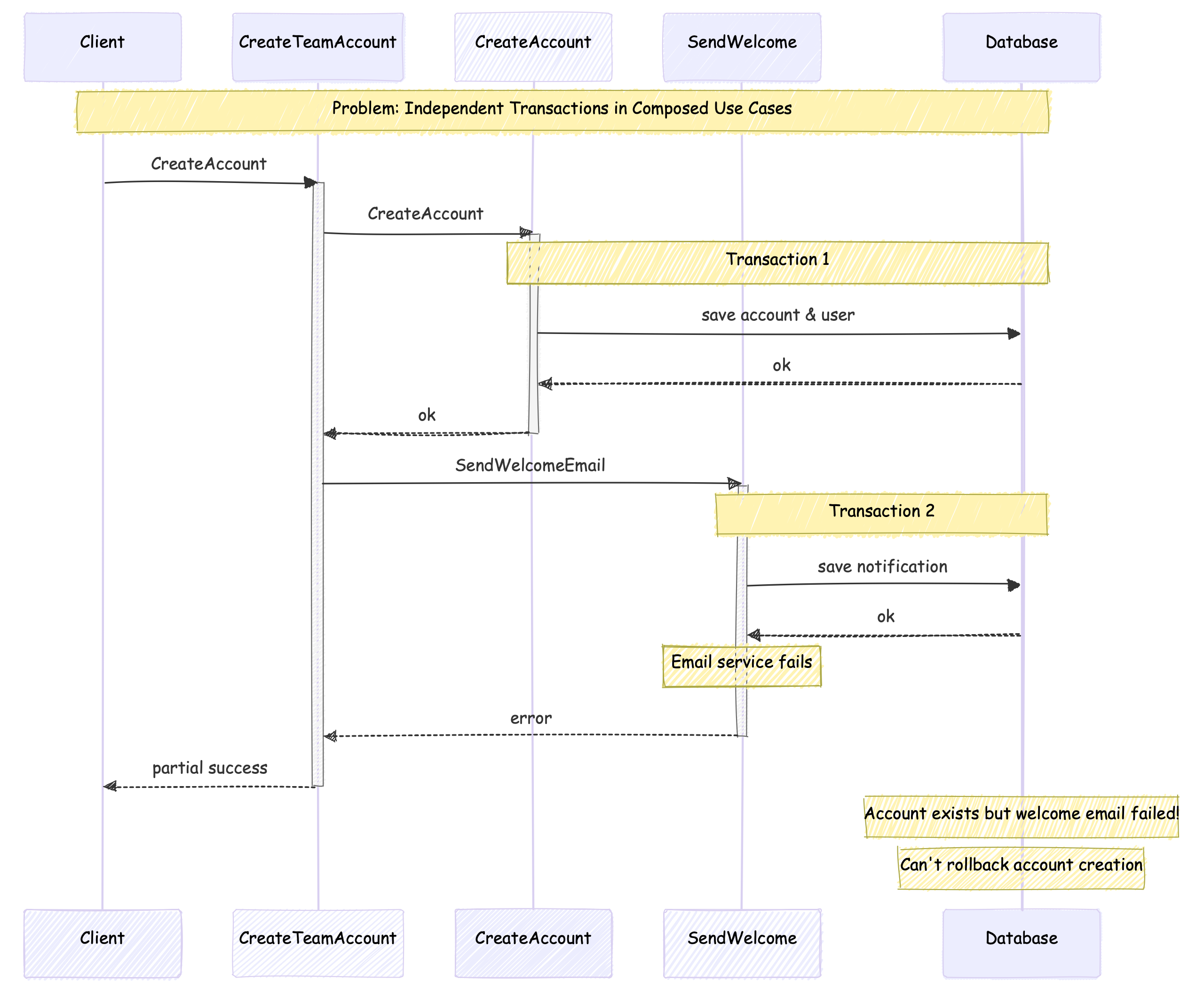
At first glance, this code appears reasonable. We create the account and then send a welcome email. But let’s think through what’s actually happening at the database level. Each use case manages its own transaction, which means we have two independent database transactions:
- The first transaction creates our account and user records
- The second transaction creates a notification record and triggers the email service
This separation creates several challenges that might not be immediately obvious:
- Transaction Composability: Each use case manages its own transaction, making it difficult to compose operations that should succeed or fail together.
- Data Consistency: Between our first and second transaction, another operation could modify the user record, leaving us working with stale data.
- Partial Failures: If the email service fails, we can’t roll back the account creation - it’s already committed. Should we retry? Log the failure? These decisions become architectural concerns.
- Optional Operations: Some operations (like welcome emails) shouldn’t prevent the main business operation from succeeding. How do we distinguish between critical and optional steps?
Moving Beyond Simple Transactions
Our journey through transaction management reveals a crucial insight: while the Unit of Work pattern solves our immediate consistency problems, enterprise applications need more sophisticated solutions. The pattern provides an excellent foundation, but we need to build upon it carefully.
I’ve seen teams struggle when their applications grow more complex. Three issues come up repeatedly:
- Mixing Technical and Business Boundaries: Transaction scope should match business operations, not technical convenience. I’ve seen many codebases where transactions start too early or end too late simply because it seemed easier to implement that way.
- Ignoring Partial Failures: Real systems fail in partial and subtle ways. The account creation succeeds, but the welcome email fails. The payment processes, but the receipt generation times out. Each failure mode needs careful consideration.
- Overloading Repositories: Keep repositories focused on domain persistence. Avoid the temptation to add transaction management or business logic, even when it seems convenient.
This brings us to the heart of the matter: how do we structure our applications so our technical implementation genuinely reflects business reality? As systems grow, developers increasingly face scenarios where some operations are critical (like creating an account) while others are optional (like sending welcome emails). They need clean ways to handle composed operations that require different transaction patterns.
In my next article, we’ll explore how nested transactions offer a powerful solution to these challenges. We’ll look at how they let developers compose complex operations while maintaining atomicity across the system and see how nested transactions create natural boundaries between critical and optional operations, enabling graceful handling of partial failures.
This is Part 2 of a series on Clean Architecture Transaction Management. Part 1 introduced the challenges, and Part 3 will explore nested transactions.