How to Deploy Often and Sleep Well
It’s 11 PM on Sunday. Your team is on Slack, coordinating the quarterly deployment. The application starts but immediately crashes—turns out the production Redis URL is different from staging. The load balancer health checks are failing because someone changed the endpoint path three commits ago. Your deployment runbook is missing step 7, and nobody remembers what it was supposed to be.
This scene plays out at thousands of companies every week. Teams that are brilliant at building software struggle when it’s time to ship it. But deployment problems aren’t inherently unsolvable. Teams just look at them as one giant, interconnected mess instead of separate, manageable challenges.
The Double Complexity Trap
Teams get caught in a cycle: they’re afraid of deploying complex changes, so they build complex processes to manage that risk. But the complex processes make deployments even scarier, so they delay them longer, which makes the changes even more complex.
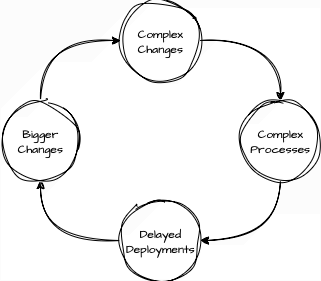
When teams think about deployment improvements, they see something like this:
We can’t deploy more often because our changes are too big and risky, and our changes are big because we deploy infrequently, and we deploy infrequently because we need extensive coordination processes, and we need coordination because our changes are complex, and we can’t simplify our changes because we need to coordinate with three teams first…
It becomes a circular dependency trap. Everything seems to depend on everything else, so teams get stuck.
Remember the last time you deployed a hotfix? Your payment system went down, and you deployed a 3-line bug fix immediately. No coordination meetings, no extensive testing cycles, no Sunday night planning. You felt completely confident pushing that change to production right away.
It was so easy to deploy a hotfix because it was different. It had neither type of complexity:
- Simple change: Three lines, clear scope, obvious impact
- Simple process: No coordination, no ceremonies, straight to production
Your regular deployments have both complexities:
- Complex changes: 47 commits, unclear interactions, broad scope
- Complex processes: Multi-team coordination, extensive testing, detailed runbooks
The hotfix succeeded because it avoided both problems. You can eliminate complex processes by keeping changes simple. Both complexities are unnecessary, and eliminating one makes it easier to eliminate the other.
The Evidence: Simple Works Better
This isn’t just theory. The DORA research shows that elite teams deploying multiple times per day consistently outperform teams with quarterly releases—not just on deployment metrics, but on overall productivity, quality, and business outcomes. Elite performers deploy 208x more frequently than low performers and recover from failures in under one hour compared to up to one month for low performers.
According to the 2024 DORA Report, elite teams maintain a 5% change failure rate or lower while achieving these deployment frequencies. These aren’t superhuman teams—they’re teams that learned to decompose complex problems systematically.
I’ve found these high-performing teams take a different approach: instead of solving complex deployment problems with more complex processes, they eliminate both types of complexity through decomposition. They follow a predictable pattern:
- Identify the specific fears behind your deployment anxiety
- Pick one fear to focus on—usually the smallest or most isolated
- Solve just that piece—ignore how it affects other problems temporarily
- Discover that solving one piece makes others easier—the web starts to untangle
- Build momentum—each small win gives confidence to tackle the next piece
The Five Common Deployment Challenges (Each Surprisingly Manageable)
Let’s examine the common deployment fears individually. Notice how each one, in isolation, has clear solutions and established patterns.
Challenge 1: Infrequent Deployments Increase Risk
Deployments are so scary that we deploy once a quarter, on Sunday nights
Why it feels impossible: When deployments happen rarely, they include massive changesets that have exponentially higher failure rates.
This isn’t irrational fear—it’s an objective reality given to us in sensation. While rigorous empirical studies on specific failure rates are limited, extensive industry analysis consistently demonstrates the relationship between batch size and risk. The DORA research team, using data from thousands of organizations, found that deployment frequency serves as a proxy for batch size, with smaller batches reducing cycle time, flow variability, and risk[1].
Practitioners consistently observe that larger changesets create exponentially more debugging complexity and integration conflicts[2]. The principle is well-established in systems theory: as the number of interactions in a system increases, the complexity grows exponentially, not linearly.
Why it’s actually manageable: You think you do infrequent deployments to manage risk, but the infrequency is actually the root cause of the risk. The solution is to deploy smaller changes more frequently, even if that means deploying an incomplete feature behind a feature flag.
Feature flags let you deploy code to production without immediately activating it for users—essentially an if/then statement that controls whether new functionality runs.
- The pattern: Feature flag deployment. Continuous integration. Small batch sizes.
Challenge 2: Testing Bottleneck
We need comprehensive end-to-end tests before we can deploy automatically
Why it feels impossible: Teams often feel like the only way they could automate deployments is by replacing rigorous manual release testing with comprehensive end-to-end test coverage.
Anyone who’s ever tried to achieve this knows how hard it is to build such a test suite. You spend months building a comprehensive Selenium test suite before attempting automated deployments. The results? The tests are flaky, fail due to minor UI changes, and take 45 minutes to run. Your deployment is still manual because you’re waiting for “perfect” test coverage.
Why it’s actually manageable: This kind of thinking doesn’t take into account the test pyramid. The foundation of your test suite—and the vast majority of your tests—should be unit tests. They help verify changes, drive development, and test your code against different kinds of inputs.
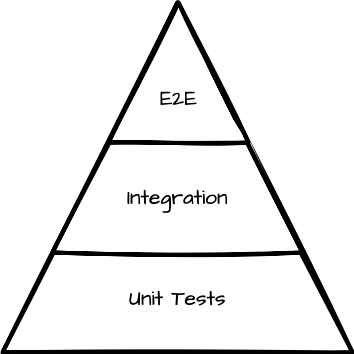
You don’t need 100% coverage to deploy. Focus instead on testing the code you’re actively changing, make sure it’s covered with extensive unit tests and a healthy amount of integration tests. Don’t forget to test your code manually before merging it—we don’t want to test after the merge, we want to merge already tested code.
Fast unit tests give you confidence in making changes, and manual verification gives you an immediate feedback loop. In contrast, pre-release testing sessions create a way-too-delayed feedback loop, making it hard to fix things that were implemented weeks or even months ago.
- The pattern: Testing pyramid. Fast feedback loops. Risk-based testing.
Challenge 3: Fear of Database Schema Migrations
Database changes are too risky for frequent deployments
Why it feels impossible: Database changes seem inherently dangerous and hard to undo. Unlike application code that you can quickly rollback, database migrations feel permanent and scary.
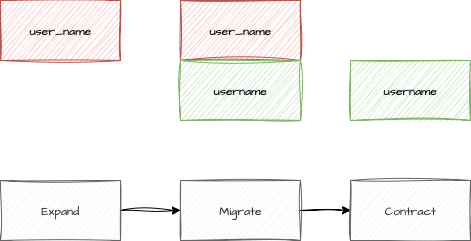
Teams often approach database changes the same way they did when deployments happened quarterly. You need to rename the
user_name column to username, so your migration drops the old column and creates the new one in a single deployment.
What happens? Downtime while old application instances crash trying to access the deleted column. Even worse, if
something goes wrong, you can’t easily rollback because the old column data is gone.
Why it’s actually manageable: The secret is learning backward-compatible migration patterns, specifically the expand-and-contract approach. Instead of changing the database schema in one risky step, you break it into safe, reversible phases.
For the column rename example: first add the new username column while keeping user_name (expand phase). Update
your application to write to both columns but read from the new one. Deploy this change safely. Then, in a later
deployment, remove the old user_name column (contract phase). Each step is backward compatible and individually reversible.
The key insight is separating schema changes from application logic changes. Deploy the database change first, then the application change that uses it. This way, you’re never in a state where the application expects something the database doesn’t have.
The root of complexity here is rare deployments–developers have to pack all the changes together. Having the ability to deploy each change independently gives you a way out: you can orchestrate the changes without downtime.
For specific implementation guidance, this strong migrations documentation provides an excellent overview of safe database migration practices, though the principles apply beyond Ruby on Rails.
- The pattern: Expand-and-contract migrations. Backward compatibility. Separate schema and data migrations.
Challenge 4: Multi-team Coordination Problems
Multiple teams can’t deploy frequently without chaos
Why it feels impossible: More deployments seem to mean more opportunities for teams to step on each other’s toes. The logic feels sound—if coordination is hard with quarterly deployments, surely it’s impossible with daily deployments.
The coordination problem gets worse with infrequent deployments, not better. Here’s a typical scenario: The frontend team can’t deploy their bug fix because it requires a database change from the backend team, which can’t deploy because the mobile team needs to update their API calls first. All three teams are blocked, waiting for a coordinated release window three weeks away.
This creates a snowball effect. By the time the release window arrives, you have dozens of changes from multiple teams that all have to work together perfectly. The coordination complexity grows exponentially.
Why it’s actually manageable: The solution isn’t more coordination—it’s less dependency. High-performing teams achieve this through clear service boundaries and API contracts testing. Each team can deploy independently because they’ve designed their interfaces to be backward compatible.
When the backend team needs to change an API, they don’t break the mobile team. Instead, they version the API or support both old and new formats temporarily. When the database team needs to add a column, they do it in a way that doesn’t break existing application code.
You need a shift from “let’s coordinate our deployments” to “let’s design for independent deployability.” Once teams can deploy without affecting each other, the coordination problem disappears.
- The pattern: Service contracts. API versioning. Backward compatibility. Independent deployability.
Challenge 5: Automation Prerequisites
We can’t set up deployment automation until we solve all these other problems first
Why it feels impossible: Automation seems to require solving every other problem as a prerequisite. You look at successful companies with their sophisticated deployment pipelines and think you need to build something equally complex before you can start.
You research deployment automation and decide you need Kubernetes, Terraform, GitOps, service mesh, and a full observability stack before you can deploy anything. You spend 3 months planning the “perfect” system while continuing to deploy manually. Meanwhile, your manual deployments are still painful and error-prone.
This is the classic perfectionism trap. You’re waiting to automate until you have the perfect process to automate, but your process will never be perfect until you start automating and learning from it.
Why it’s actually manageable: Start with simple automation for one piece of your deployment process, even if everything else stays manual. Automate just the build step, or just the database backup step, or just the service restart step. Even these small automations save time and reduce errors.
Automation is not a binary choice—it’s a spectrum. You don’t need to go from completely manual to completely automated overnight. Each small automation teaches you something and makes the next step easier.
Include basic error monitoring from the start with tools like Sentry or Bugsnag that integrate in a few lines of code and immediately alert you when deployments introduce new exceptions or errors. You don’t need complex observability platforms initially—these simple tools catch obvious problems within minutes of deployment and provide stack traces to debug issues quickly.
Once you automate the most painful step, you’ll quickly see where the next bottleneck is. Maybe it’s running tests, or uploading files, or updating configuration. Automate that next. This incremental approach lets you learn as you go and build exactly what you need, not what you think you might need.
- The pattern: Incremental automation. Start simple, evolve gradually. Automate the most painful step first.
Where to Start
Now that you can see each challenge is manageable in isolation, think of which deployment aspect causes you the most anxiety and focus there first.
Complex changes that are hard to debug when they break? Focus on deployment frequency. Start with smaller, more frequent deployments, even behind unused feature flags.
Uncertainty whether changes work in production? Address your testing strategy. Audit your current tests and replace one flaky end-to-end test with faster unit tests.
Database changes breaking things unpredictably? Learn backward-compatible patterns. Research expand-and-contract migrations and try one as an experiment.
Endless team coordination making deployments feel chaotic? Reduce dependencies. Map shared databases and APIs, then discuss service boundaries with one team.
Manual effort and error-prone deployment steps? Begin incremental automation. Pick your most painful manual step and automate just that piece.
Keep the momentum
Solving one piece of this puzzle makes other pieces dramatically easier. This isn’t just feel-good motivation—it’s a predictable pattern.
When you fix your testing strategy, database changes become less scary because you can verify they work before deploying. When you implement feature flags, team coordination becomes simpler because you can deploy code without immediately affecting users. When you add basic automation, deployment frequency stops feeling risky because the mechanics are reliable and reproducible. When you deploy smaller changes, debugging becomes trivial because you know exactly what changed.
The problems that seemed impossibly interconnected start untangling themselves!
Start This Week
Don’t try to tackle everything at once. Pick the challenge that resonates most and make one small improvement. Deploy one change behind a feature flag you never turn on. Replace one flaky test with three unit tests. Try one backward-compatible database migration. Automate one manual step.
These aren’t complete solutions – they’re experiments that prove the web of problems isn’t as tangled as it seems. Your next deployment just has to be one small step better than your last one.
That’s how teams go from Sunday night deployment anxiety to deploying with confidence multiple times per day. One small step at a time.